Instant Multi-View Head Capture through
Learnable Registration
Timo Bolkart Tianye Li Michael J. Black
CVPR 2023
[Paper] [Supplemental PDF] [Video] [Code] [Poster] [FaMoS dataset]
{kind=link}
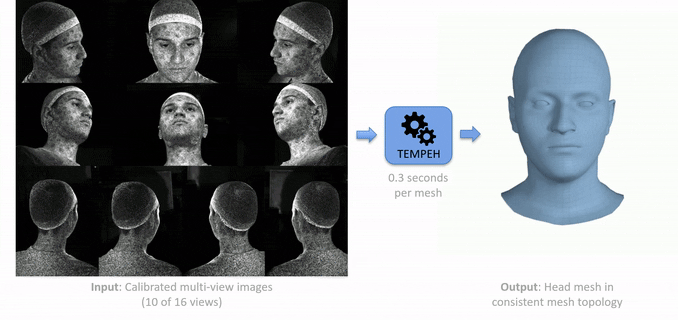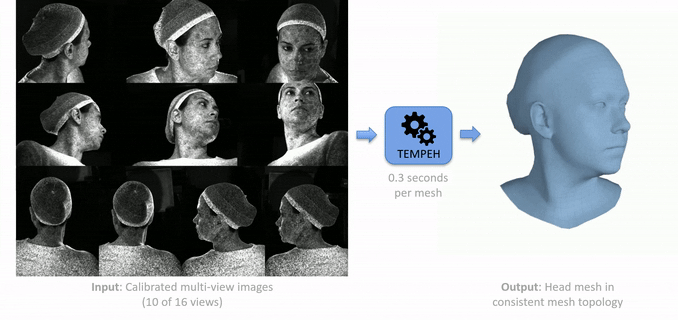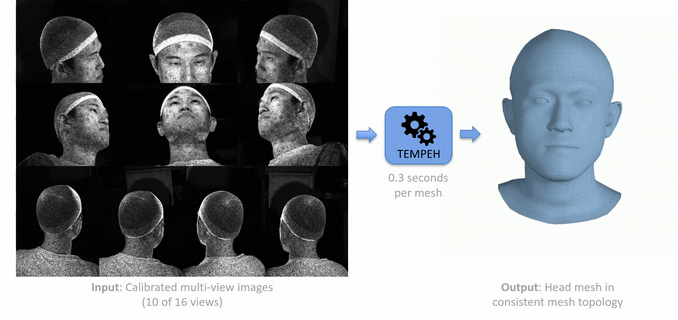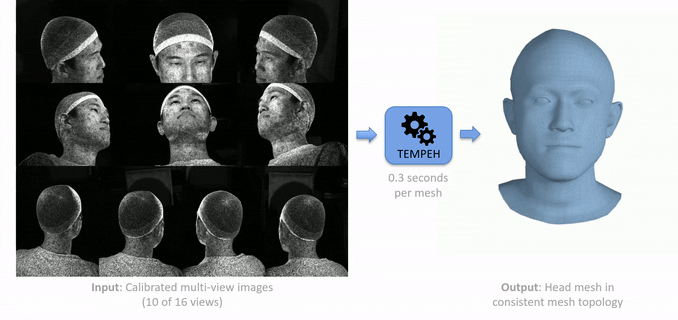 TEMPEH: Given calibrated multi-view images (left), TEMPEH directly infers 3D head meshes in dense semantic correspondence (right) in about 0.3 seconds. TEMPEH reconstructs heads with varying expressions and head poses for subjects unseen during training. Applied to multi-view video input, the frame-by-frame inferred meshes are temporally coherent, making them directly applicable to full head performance capture applications.
TEMPEH: Given calibrated multi-view images (left), TEMPEH directly infers 3D head meshes in dense semantic correspondence (right) in about 0.3 seconds. TEMPEH reconstructs heads with varying expressions and head poses for subjects unseen during training. Applied to multi-view video input, the frame-by-frame inferred meshes are temporally coherent, making them directly applicable to full head performance capture applications.
Abstract
Existing methods for capturing datasets of 3D heads in dense semantic correspondence are slow, and commonly address the problem in two separate steps; multi-view stereo (MVS) reconstruction followed by non-rigid registration. To simplify this process, we introduce TEMPEH (Towards Estimation of 3D Meshes from Performances of Expressive Heads) to directly infer 3D heads in dense correspondence from calibrated multi-view images. Registering datasets of 3D scans typically requires manual parameter tuning to find the right balance between accurately fitting the scans’ surfaces and being robust to scanning noise and outliers. Instead, we propose to jointly register a 3D head dataset while training TEMPEH. Specifically, during training we minimize a geometric loss commonly used for surface registration, effectively leveraging TEMPEH as a regularizer. Our multi-view head inference builds on a volumetric feature representation that samples and fuses features from each view using camera calibration information. To account for partial occlusions and a large capture volume that enables head movements, we use view- and surface-aware feature fusion, and a spatial transformer-based head localization module, respectively. We use raw MVS scans as supervision during training, but, once trained, TEMPEH directly predicts 3D heads in dense correspondence without requiring scans. Predicting one head takes about 0.3 seconds with a median reconstruction error of 0.26 mm, 64% lower than the current state-of-the-art. This enables the efficient capture of large datasets containing multiple people and diverse facial motions. Code, model, and data are publicly available.
Video
TL;DR
- TEMPEH reconstructs 3D heads in semantic correspondence directly from calibrated multi-view images.
- Predicting one head takes about 0.3 seconds.
- TEMPEH leverages ToFu's volumetric feature sampling framework.
- Self-supervised training from scans overcomes ambiguous correspondence across subjects and imperfect correspondence across expressions.
- A spatial transformer module localizes the head in the feature volume, which enables the handling of a large capture volumes by focusing on the region of interest.
- A surface-aware feature fusion accounts for self-occlusions.
FaMoS Dataset
FaMoS is a dynamic 3D head dataset from 95 subjects, each performing 28 motion sequences. The sequences comprise of six prototypical expressions (i.e., Anger, Disgust, Fear, Happiness, Sadness, and Surprise), two head rotations (left/right and up/down), and diverse facial motions, including extreme and asymmetric expressions. Each sequence is recorded at 60 fps. In total, FaMoS contains around 600K 3D head meshes (i.e., ~225 frames per sequence). For each frame, we compute a registration in FLAME mesh topology, which are downloadable here for research purposes. You must sign up and agree to the license to download the data.

FaMoS dataset: Randomly sampled registered sequences in FLAME mesh topology.
Referencing TEMPEH
@inproceedings{TMPEH:CVPR:2023,
title = {Instant Multi-View Head Capture through Learnable Registration},
author = {Bolkart, Timo and Li, Tianye and Black, Michael J.},
booktitle = {Conference on Computer Vision and Pattern Recognition (CVPR)},
pages = {768-779},
year = {2023}
}